Нейросети давно перестали быть чем-то из будущего — они уже здесь, и их используют повсеместно: от создания текстов до анализа данных и построения бизнес-процессов. Однако всё чаще разработчики и энтузиасты обращают внимание не на облачные API, а на локальный запуск моделей — прямо у себя на компьютере. Это открывает массу возможностей: эксперименты без ограничений, интеграция в собственные проекты и полный контроль над моделью.
При этом качество современных открытых LLM уже давно вышло на уровень, где их можно использовать не только для тестов, но и в реальных задачах. Даже на скромном железе. В этой статье мы расскажем, как запустить нейросеть локально на видеокарте AMD или Nvidia, какие результаты можно получить.
Технические характеристики
Запуск происходил на системе с такими характеристиками:
- Видеокарта: AMD RX 480 (8 ГБ VRAM)
- ЦПУ: Ryzen 7 3700
- ОЗУ: 16 ГБ
- ОС: Windows 10 x64
- Версия KoboldCPP: бинарная, без CUDA
KoboldCPP оказался единственным решением, стабильно работающим на этом железе. Большинство альтернативных программ запускались только на CPU, что делало скорость генерации неприемлемой для практического использования.
KoboldCPP что это?
KoboldCPP — это легковесный LLM-интерфейс с поддержкой GGUF-моделей, разработанный для локального запуска языковых моделей. Существуют отдельные версии программы для систем с CUDA и без, что делает её универсальным решением для владельцев как NVIDIA, так и AMD видеокарт. Главная особенность — акцент на производительность и совместимость. Программа предоставляет веб-интерфейс, а также API для работы с нейросетью.
GGUF (Groked GGML Unified Format) — наиболее оптимальный на сегодняшний день формат для локального запуска. Благодаря ему, KoboldCPP может эффективно работать даже на системах с ограниченными ресурсами.
Установка и запуск
1. Скачиваем нужную версию KoboldCPP с GitHub. Для рассматриваемой системы выбираем версию _nocuda.
2. Скачиваем файл языковой модели. Для примера возьмем Llama-3.1-8B в версии Q4_K_M.

3. Запускаем KoboldCPP, выбираем скаченную модель и нужную конфигурацию
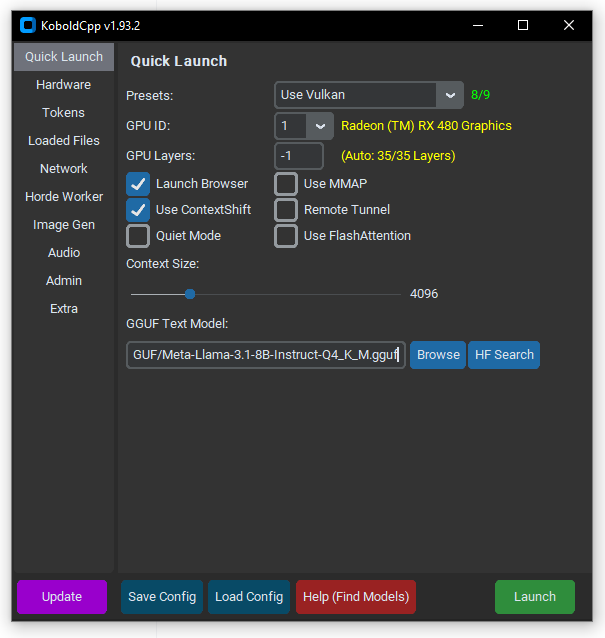
После этого модель загрузиться в оперативную память видеокарты и запустится веб-интерфейс программы.
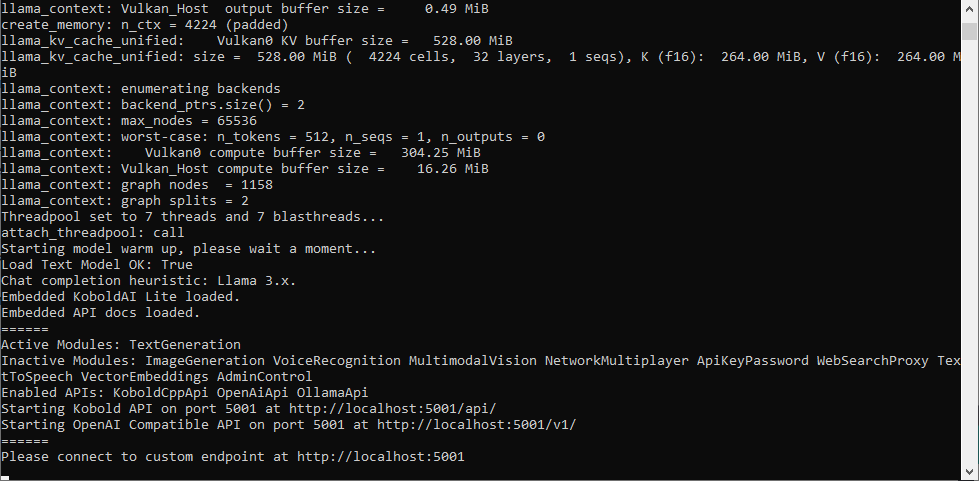
Результаты: 13,2 токена/с для 8B
В ходе тестирования удалось добиться скорости генерации текста на уровне 13,2 токена в секунду. Для сравнения — это почти как разговор в реальном времени.
Формат квантования Q4_K_M позволяет значительно снизить требования к памяти и производительности, почти не теряя в качестве генерации. Это отличное решение для тех, кто хочет запустить полноценную LLM у себя дома без лишних затрат на оборудование.
Чат и API
KoboldCPP предлагает два основных режима взаимодействия с языковой моделью:
- Чат через веб-интерфейс — запускается локальный сервер, доступный в браузере. Интерфейс прост, удобен для тестирования моделей, написания текстов или диалога.
- API — позволяет использовать модель в сторонних приложениях. API-сервер запускается автоматически при загрузке модели, после чего становится доступным адрес
/api/v1/generate. На него можно отправлять JSON-запросы с параметрами prompt, max_tokens и другими. Это удобно для интеграции в локальные ассистенты, инструменты автоматизации и другие проекты.
Подробная документация для API находится по адресу /api/.
Запуск локальной модели требует ресурсов и времени на настройку. Но если вы хотите сразу приступить к работе с ИИ без лишних усилий обратите внимание на Chad AI (Реклама). Это доступный и удобный инструмент который работает без VPN. Он объединяет в одном окне ряд популярных нейросетей, которые позволяют писать тексты, статьи, код и создавать изображения.
Выводы
KoboldCPP отличное решение для тех, кто не обладает современным графическим процессором. На AMD RX 480 при грамотной настройке возможно достичь весьма неплохих результатов. Ответ генерируется быстро, а сервер не падает при длинных промптах.
Конечно, локальная модель пока не тянет на уровень самых передовых нейросетей вроде ChatGPT или Claude. В отдельных случаях ответы могут быть менее точными, а логика — не такой стройной. Однако это не приговор: часть проблем обходится с помощью хорошо прописанного промта и расширенного контекста. Чем подробнее запрос и чем больше подсказок вы дадите модели — тем ближе к качеству «облачных» решений станут результаты.



